TL;DR
如果使用來源資料庫成熟的 Write-Ahead Logging (WAL) 機制例如 MySQL binlog (Binary log), PostgreSQL WAL 或成熟工具如 Kafka Connector for PostgreSQL/MySQL, AWS DMS (Database Migration Service) 的話,則通常不會遇到這個問題
場景
希望將某資料庫中的 source_table 同步到 Apache Iceberg 格式的 target_table 中,其中
- 透過某種自幹的方式取得 source_table 的 CDC 事件並將資料送到 Apache Kafka
- 以 Apache Kafka 來串流 CDC 事件
- 使用 Apache Spark 從 Apache Kafka 讀取資料,然後處理資料及寫入資料表
問題可能是怎麼來的
工程面
- 將 CDC 事件以平行非同步的方式發送到 Kafka
- ex. 後端 (Backend) 程式在執行資料庫操作之後以非同步的方式將異動資料寫到 Apache Kafka
- ex. 透過定時執行一段 SQL 取得 source_table 的 CDC 事件然後以平行非同步的方式發送到 Kafka
- 擷取 CDC 事件的時候為了省流量 (降低延遲) 就沒有包含完整記錄 (Record) 資訊。註解:這在同質關聯式資料庫之間做資料同步是可行的
資料面: FULL 或 Partial
先假設 source_table 有欄位: PK, col_1, col_2, col_3, updated_time 如下圖
| PK | col_1 | col_2 | col_3 | updated_time |
|---|---|---|---|---|
| 1 | aaa11 | bbb11 | 11111 | 2025-01-01 00:00:00 |
| 2 | aaa22 | bbb22 | 22222 | 2025-01-01 00:00:00 |
我們分別在不同時間點執行以下 SQL statements
1 | -- statement 1 |
異動後的 source_table 如下圖
| PK | col_1 | col_2 | col_3 | updated_time |
|---|---|---|---|---|
| 2 | aaa22 | bbb22 | 0.002 | 2025-01-01 00:00:02 |
| 3 | aaa33 | bbb33 | 33333 | 2025-01-01 00:00:03 |
這裡我們需先知道:從來源資料庫送出來的異動後資訊稱為 after_image (變更後的狀態),after_image 通常 是以下兩種形式
通常 CDC 事件會有兩個重要的添加欄位 (以下用
_action和_timestamp表達):
- _action 欄位: 用以表達這個事件的操作,例如 insert, delete, update
- _timestamp 欄位: 用以表達這個事件的時間戳記
Full: 表示包含完整的資料列 (以下範例已 JSON 表示)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31{
"after_image": [
{
"_action": "_delete",
"_timestamp": "2025-01-01 00:00:01",
"PK": 1,
"col_1": "aaa11",
"col_2": "bbb11",
"col_3": 11111,
"updated_time": "2025-01-01 00:00:00"
},
{
"_action": "_update",
"_timestamp": "2025-01-01 00:00:02",
"PK": 2,
"col_1": "aaa22",
"col_2": "bbb22",
"col_3": 0.002,
"updated_time": "2025-01-01 00:00:02"
},
{
"_action": "_insert",
"_timestamp": "2025-01-01 00:00:03",
"PK": 3,
"col_1": "aaa333",
"col_2": "bbb333",
"col_3": 33333,
"updated_time": "2025-01-01 00:00:03"
}
]
}Partial: 僅包含主鍵和異動欄位 (以下範例已 JSON 表示)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25{
"after_image": [
{
"_action": "_delete",
"_timestamp": "2025-01-01 00:00:01",
"PK": 1
},
{
"_action": "_update",
"_timestamp": "2025-01-01 00:00:02",
"PK": 2,
"col_3": 0.002,
"updated_time": "2025-01-01 00:00:02"
},
{
"_action": "_insert",
"_timestamp": "2025-01-01 00:00:03",
"PK": 3,
"col_1": "aaa333",
"col_2": "bbb333",
"col_3": 33333,
"updated_time": "2025-01-01 00:00:03"
}
]
}
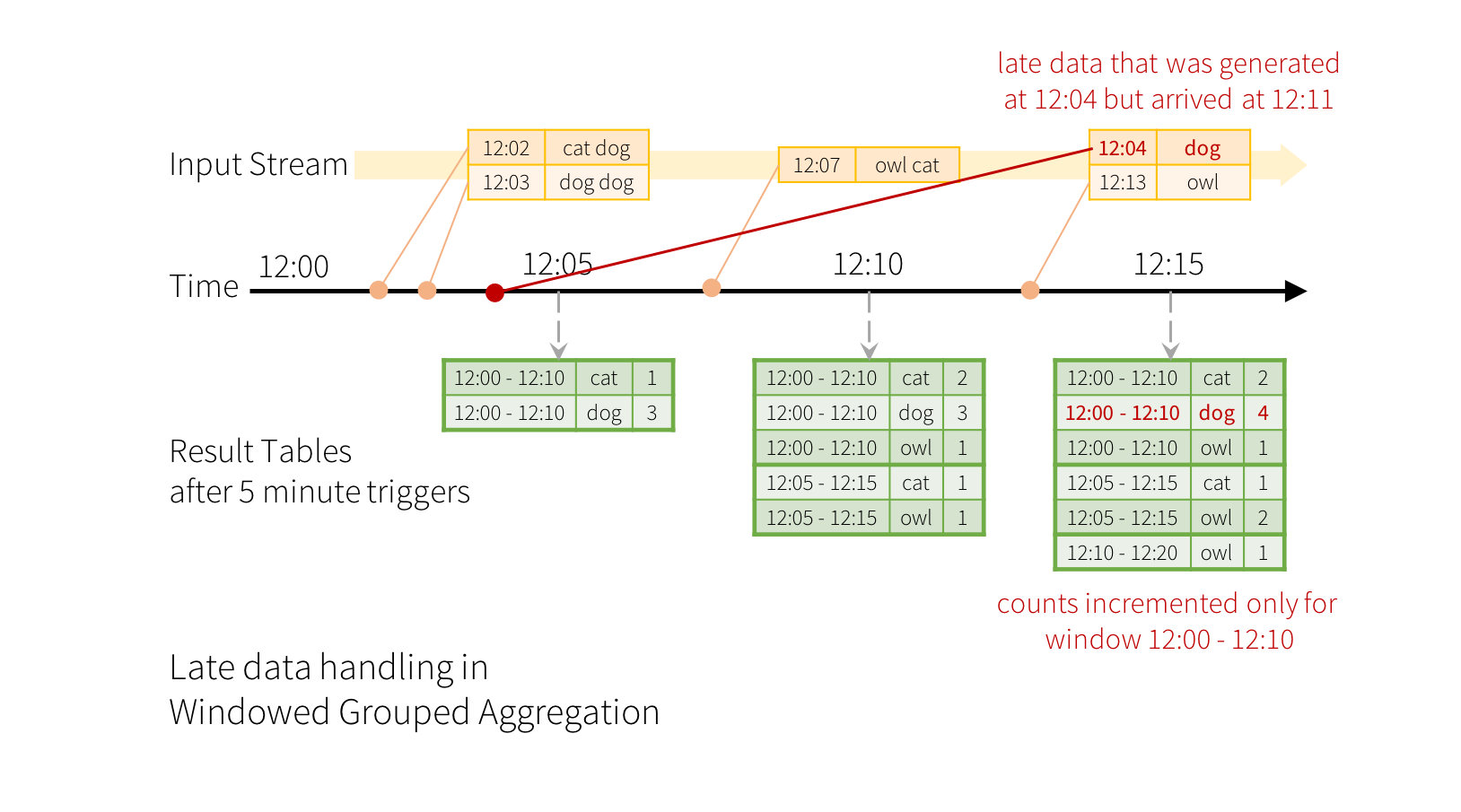
Streaming processing (流氏處理) 面: Late Data (遲到的資料)
理想上,我們期望事件都是依照 event timestamp (事件時間戳記) 循序的被 Apache Spark Strutected Streaming 接收到,如下圖
來源為 Apache Spark 官方文件:handling-late-data-and-watermarking
問題分析和解決
當 after_image 是 Full 格式的時候
這裡的核心概念是:我們只需要一直去比對異動資料是否比目的資料更新鮮即可
當我們可以保證 after_image 是 Full 的格式的時候,下游的 Spark Structured Streaming 不需要在乎接收到的事件是否依照 updated_time 排序也可以輕鬆在 foreachBatch 中使用 Window Function 先將 micro-batch 進行一次重排序並只取最新一筆紀錄然後再執行 MERGE 指令,如此就能將資料保持 eventually consistent (最終一致)。以下為範例
1 | ''' |
1 | -- spark.sql(merge_statement) |
當 after_image 是 Partial 格式的時候
如果是同質的關聯式資料庫之間的同步,或者說 row-based (行式) 儲存的話,則 partial 格式是相對有效率又節省頻寬
在 after_image 是 Partial 格式並且是要將資料同步至 Lake House (資料湖倉) 的時候,會遇到的幾個問題是:
- 不容易實現平行處理
- Lake House 通常是 column-based (列式) 儲存,對於”更新”某行中的某幾列是相對沒效率 (可以想成磁頭需要移動比較多次,可參考 Apache Parquet - File format 想像)。
如果非要處理的話,可以使用 Entity-Attribute-Value (EAV) 資料結構或者可以稱之為 long and skinny table (長且窄的表)
以下為簡易架構圖:
flowchart LR
source@{ shape: database, label: "Source table
(RDBMS)" }
event@{ shape: rounded, label: "Event
(Changed Data)" }
kafka@{ shape: das, label: "Kafka" }
sss@{ shape: rect, label: "Spark Structured Streaming" }
long@{ shape: lin-cyl, label: "EAV table
(Iceberg)" }
target@{ shape: lin-cyl, label: "Target table
(Iceberg)" }
source --> event --> kafka -->|1/ subscribe| sss
sss -->|2/ Unpivot and Merge|long
long -->|3/ Changed Data Capture|sss
sss -->|4/ Pivot and Replace|target
最後附上範例程式碼 Gist: iceberg_spark_cdc_sample.py